
Introduction to PyTorch
Being the leader of the deep learning framework so far, PyTorch has had a fast rise in popularity amongst researchers and developers alike. The reasons are its intuitive design, dynamic computation graph, and strong community support, which makes it a robust resource for building and deploying the highest technologies in AI models. Compared to its primary competitor, TensorFlow, PyTorch has a more Pythonic feel, which helps make it easier to learn and use for those who are already familiar with Python’s ecosystem. In this blog post, you will discover all the details about PyTorch, its core components, utilities, and the advantages of using PyTorch, an example of TensorFlow and how it compares with PyTorch, and how you can use PyTorch in the real world.
In this post, we will explore PyTorch tensors — the main building blocks on which PyTorch is built and how PyTorch’s dynamic computation graph separates it from the other frameworks. Now, we will see a load of use cases in production environments that make PyTorch preferable for many in the field.
The flexibility and extensibility are the basis for PyTorch’s appeal, but it is also easy to use. Unlike the static graph of TensorFlow, where you never know what you’re actually going to compute, its dynamic computational graph in TensorFlow terms is known as eager execution. It is much more intuitive to debug and experiment on. Because all operations run to completion immediately, all errors can be tracked, and the flow of data can be monitored as the development process happens. The interactive nature is beneficial to research: quick iteration and experimentation with new ideas. Learn more about the Best Graphics Card for Machine Learning.
Additionally, PyTorch has an excellent ecosystem of tools and libraries, making the process of building complex models and deploying them to different platforms less daunting. A combined complete ecosystem along with an active and vibrant community to have support ready at hand in case of any issues that come up.
What is PyTorch?
Originally a research project of Meta’s AI Research lab, PyTorch is an open-source and flexible tool and library designed to build and deploy dynamic computing and auto-grad frameworks for machine learning (ML) applications, mainly for Python. Just like other ML applications, PyTorch is often used for building, training, and testing deep learning networks.
What is PyTorch Tensor?
The tensor is at the core of PyTorch and is a multi-dimensional array, the basic array type used for representing and processing data. Similar to NumPy arrays, PyTorch tensors also offer the Pythonic interface and additional capabilities that are specifically built for deep learning tasks. They are swift in terms of computation and are highly optimized for GPU acceleration to the point that computations are orders of magnitude faster than CPU-based ones. In reality, many algorithms are slow to compute, and they depend on massive datasets and very complicated computations to train complex deep-learning models. This acceleration is significant for such training. There are many sources for creating PyTorch tensors, NumPy arrays, lists, and other tensors.
Besides mathematical functions and linear algebra operations, they support a wide range of operations. It also makes it easy to integrate seamlessly with NumPy, as NumPy handles simple data transfer and can manipulate these two frameworks within each other. Most of the work you will be doing with PyTorch will involve working with tensors to perform all the computations and build the model. Therefore, understanding how tensors work in PyTorch is fundamental. PyTorch tensors are flexible, and GPU acceleration makes them incredibly powerful for deep learning.
Although PyTorch has multiple tensor types available, it has been created to address different data types and computational needs. This is an example of creating tensors of floating point numbers (float32, float64), integers (int32, int64), or booleans. The selection of a proper data type is essential for saving memory and reducing computational overhead.
In addition, automatic differentiation is supported by PyTorch tensors, which is an essential feature that allows for the efficient computation of gradients during the training process of neural networks. It comes with the capability of automatic differentiation, allowing you not to have to know or compute gradients manually, which can often be complex and error-prone. It tracks the operations on tensors automatically so it can calculate gradients without effort, which is a critical aspect of backpropagation, the algorithm used to update the weights of a network during training.
How PyTorch Works?
The fundamental design of PyTorch depends on building computational graphs during program execution. The system builds dynamic graphs while running, unlike previous static graph construction methods found in TensorFlow. From this perspective, operations go straight into execution without making an intermediate graph. It produces many benefits because it operates in real-time. Firstly, it simplifies debugging. The absence of an execution wait lets developers find and fix problems with less effort. Finding errors in a built graph requires handling the entire process to figure out where the issues exist.
Research shows that the dynamic system of PyTorch offers better control and flexibility options. The running system freely calculates the computation graph while allowing you to modify it based on results or custom conditions. Research projects need both test-and-try methods, and this flexibility makes them possible. In case you need complete knowledge of the graph beforehand, a Static graph framework shows limitations for dynamic settings. The feature helps process variable-length data while remaining adaptable to unknown algorithm structures. We pick PyTorch because it handles such data patterns expertly and serves tasks needing complicated dynamic information.
PyTorch controls dynamic computational graphs through the automatic differentiation system called autograd. The autograd system detects tensor operations to make gradient calculation an automatic task for users. The network requires gradients to train through backpropagation, so we need this system. The efficient autograd system makes deep learning model training much more manageable because users no longer need to compute gradients manually. PyTorch delivers high performance and ease of use because it combines automatic computation with an automatic differentiation engine. You can customize and add new functions to PyTorch because its design includes separate blocks that developers can adjust.
PyTorch Modules
The core reason PyTorch feels natural to work with relates to its built-in component system. A PyTorch Module contains specific blocks with built-in functionalities, including neural network layers. Our built modules create advanced models through simple design to improve our code’s usability and longevity. The nn. module of PyTorch offers us multiple built-in modules that include linear, convolutional, recurrent, and activation functions to develop neural networks. Our deep learning models work better with pre-built modules as developers can concentrate on designing the architecture while the framework handles detailed implementation.
Users build unique nn. Module-class derived components through this system. They can create unique layer components inside the framework using their requirements. Built-to-order operations and technical designs require special attention because research and development often require these features. Pytorch becomes more flexible because its developers can rapidly build and add custom modules smoothly. This design structure lets developers split large projects into smaller parts that help keep their code structure clear and build advanced models from essential components. This method enables developers to save time and energy while using existing code.
PyTorch design choice allows developers to make readable code that remains easy to update. PyTorch splits large models into smaller defined parts that help organize coding to make it simpler and easier to study, locate errors, and update as needed. Multiple developers rely on PyTorch for big development projects with various participants. Each PyTorch module structure allows for better code execution because you can perform tasks independently. Custom modules with excellent performance make the PyTorch framework the primary option for deep learning use and scientific study.
PyTorch Use Cases
Being versatile and with powerful features, PyTorch is used for a wide range of deep learning applications, from small projects to large-scale systems. It has achieved strong performance, is easy to use, and has been a popular choice for both academic research and industrial deployments. The use of PyTorch is especially common in computer vision tasks such as image classification, object detection, and image segmentation. This is made possible with all pre-trained models like ResNet, Inception, and EfficientNet, which are already available and plug and play in PyTorch, which significantly accelerates the development. It’s the central factor in obtaining state-of-the-art results in computer vision tasks because the framework works so well in dealing with large sets of data and complex models.
Natural Language Processing (NLP) benefits immensely from PyTorch’s capabilities. Recursive models of PyTorch that include RNNs along with LSTMs and transformers enable the solution of linguistic tasks such as translation systems and text categorization and sentiment evaluation functions. The framework successfully solves challenging NLP problems because it has two main strengths: sequential data processing abilities and GPU acceleration support. The rapid prototyping and final optimization process receive substantial benefits through the built-in inclusion of pre-trained language models BERT and GPT in the PyTorch framework.
Explore the Full article on the Uses of GPU.
In addition to computer vision and NLP applications, PyTorch can operate in various other domains. The flexible nature of PyTorch allows professionals to develop advanced reinforcement learning algorithms commonly used in the educational field of reinforcement learning through environmental interaction. One key benefit in reinforcement learning becomes possible through dynamic computation graphs because the environmental reactions and operator actions can modify the execution sequence dynamically. The sequential data characteristics in time series analysis make PyTorch equally suitable for this work. The application of forecasting depends on its usage throughout financial domains and healthcare industries alongside meteorology.
Generative models serve to complete data instances by creating similar entries, while PyTorch provides support for this capability. Through PyTorch, developers can easily create realistic images, videos, and text through the implementation of straightforward GANs and VAEs. The platform guides developers in creating new generative model designs, which they can utilize for specific applications. PyTorch displays broad field applicability, which demonstrates its versatility in deep learning and its ability to act as a leading framework.
PyTorch Features
PyTorch has a number of distinct features and benefits, the most notable include:
- Intuitive: Pythonic design and dynamic computation graphs simplifies and streamlines the debugging process.
- Outstanding NVIDIA GPU support: Lightning fast tensor calculations and powerful GPU acceleration with seamless CUDA support.
- Distribution of Training: Multiple GPUs and computers can be used to scale training thanks to (torch.distributed) robust tools.
- TorchScript: Non-Python environments that are high-performance and require model serialization and optimization can deploy models.
- Diverse Ecosystem: Extending its power are libraries of higher levels such as TorchText, TorchVision, and PyTorch Lightning.
PyTorch in Production
Besides working with computer vision and natural language processing tasks, PyTorch also has multiple other uses. The flexibility of PyTorch’s design helps developers create brutal reinforcement learning methods for environment interactions in the field of AI training. The dynamic feature of computation graphs works excellently with reinforcement learning because it lets actions and environment responses affect how data is processed at runtime. PyTorch works in time series analysis because it handles data sequences directly. The system plays a core role in predicting business developments across financial institutions, healthcare facilities, and weather-tracking services.
PyTorch supports generative models that create new matched data points based on available data. PyTorch lets developers build both GANs and VAEs to make realistic versions of images, videos, and text speedily. The framework makes it possible for researchers to construct original creative model designs that they can adapt to specific professional needs. Pytorch supports a wide range of tasks because it applies to various disciplines.
Making PyTorch models ready for production requires choosing appropriate hardware and software components. To speed up inference operations, you must use GPU acceleration whenever possible. An effective memory-handling system matters most while working with significant datasets and large neural networks. Setting up gradient checkpointing can decrease training memory usage while optimizing the data loading process helps model performance better. When the community develops better library options for producing work, the final product will be easier to deploy at scale.
PyTorch vs TensorFlow
PyTorch and TensorFlow are both used for building machine learning models, but they work in different ways. The comparison below shows how they differ in usage, performance, and development approach.
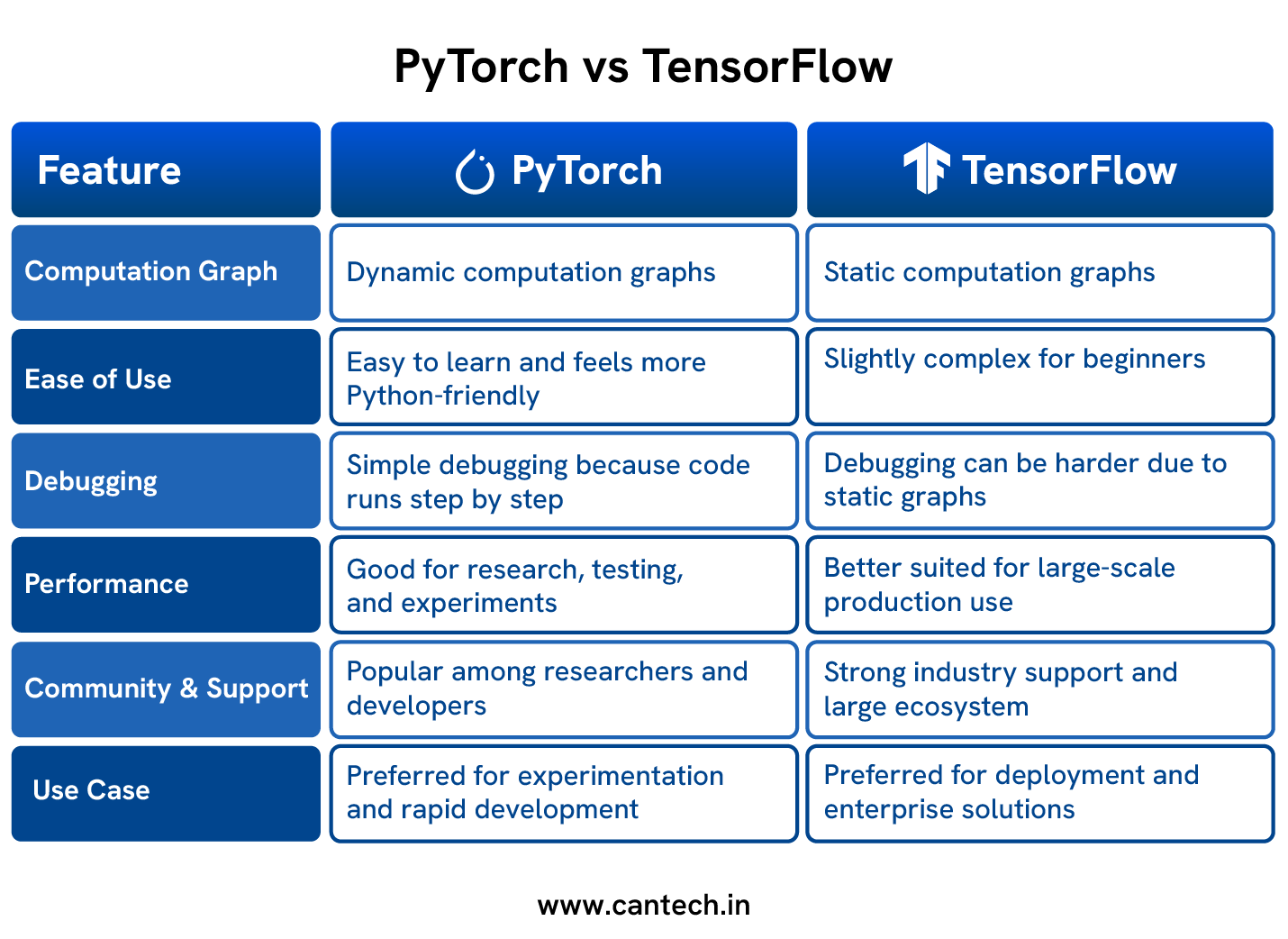
Why PyTorch? A Summary of Key Advantages
Many elements make PyTorch the preferred deep learning development framework for this model’s popularity. The interactive analysis system makes research and testing more manageable, and this model serves developers perfectly. Direct operation execution makes development more interactive and slow-paced, too. Learning Python through this system proved simple, both in terms of studying and putting it into action. The framework’s simple setup reduces deep learning entry requirements, allowing more people to utilize the technology.
The community around this framework provides helpful documents and teaches proper usage alongside offering support services. The active participant group within the framework makes updates possible and assists in overcoming technical problems with successful results. The open access to pre-trained models with basic libraries quickens development processes for everyone. When you put pre-trained models under your work, they provide a good starting point that saves time because you need less training data.
The framework’s flexibility and extensibility allow for the seamless integration of custom modules and operations, catering to the specific needs of individual projects. This adaptability is crucial for research and development, where the need for novel architectures and custom functionalities is frequent. Furthermore, PyTorch’s support for GPU acceleration significantly improves training speed and efficiency, enabling faster iteration and experimentation. This efficient computation is essential for handling the large datasets and complex models that are common in modern deep learning.
Applications of PyTorch
Many tools and frameworks in both research and business utilize PyTorch. Some examples include:
- Research: PyTorch quickly became the go-to platform for most research and development of new ML architectures.
- Computer Vision: Image classification and object detection (YOLO) and generation.
- Natural Language Processing (NLP): Meta’s large language models, machine translation, and text classification.
- Generative AI: Image generation (Stable Diffusion) and other creative AI.
- Autonomous Systems: Robotics and self-driving cars perceptual systems.
Conclusion
PyTorch stands out as a preferred deep learning framework because it combines user-friendliness with powerful features, leveraging the Best GPU for deep learning to build and release AI models of the highest standard. Its dynamic graph and built-in automatic differentiation with extensive tools ease development for both research professionals and software engineers to use. The framework handles multiple tasks well and grows quickly to support new applications while remaining practical for different computer vision and related uses without losing the ability to develop faster. The system succeeds today because people actively support it. Explore the full article on Why Choose PyTorch GPU Servers for Faster AI Model Training & Experimentation.
FAQs
What is the main difference between PyTorch and TensorFlow?
PyTorch uses a dynamic computation graph, making debugging easier and offering more flexibility. TensorFlow, while now supporting eager execution, traditionally relied on a static graph, potentially offering performance advantages in production.
What Does PyTorch Do?
PyTorch helps in building robust and intricate neural networks with the help of tensor computing (similar to NumPy but with GPU acceleration), deep learning algorithms, and other numerous features.
What is PyTorch used for?
In the creation and training of deep learning models employed in research (new AI), and in the production applications (NLP, computer vision) and generative AI technologies, it is most commonly used.
What are PyTorch tensors?
PyTorch tensors are multi-dimensional arrays, similar to NumPy arrays but optimized for GPU acceleration and deep learning operations. They are the fundamental data structure in PyTorch.
How does PyTorch’s dynamic computation graph work?
Unlike static graphs, PyTorch’s dynamic graph is built on the fly during execution. This allows for immediate execution of operations, simplifies debugging, and enables greater flexibility in model design.
What are some real-world applications of PyTorch?
PyTorch is used extensively in computer vision (image classification, object detection), natural language processing (machine translation, sentiment analysis), and reinforcement learning, among many other applications.
Is PyTorch suitable for production deployment?
Yes, PyTorch offers tools like TorchServe for cloud deployments and supports techniques like model quantization and pruning for efficient deployment on resource-constrained devices.
What is Autograd in PyTorch?
Autograd is PyTorch’s automatic differentiation engine. It automatically computes gradients of tensors, making it incredibly easy to train neural networks using backpropagation.
What is PyTorch in Python?
The PyTorch project is an open-source library developed specifically for machine learning in Python. Its architecture was based on the Torch Framework. While initially used for Computer Vision, today, it also supports a range of other applications, including Natural Language Processing (NLP).
How does PyTorch handle GPU acceleration?
PyTorch seamlessly integrates with CUDA, allowing you to quickly transfer tensors to and from your GPU for significantly faster computation, especially during training and inference. Explore the full article on What is Nvidia CUDA.
What are some popular pre-trained models available in PyTorch?
PyTorch provides access to numerous pre-trained models through torchvision (for computer vision) and torchtext (for natural language processing), including ResNet, Inception, BERT, and many others, saving significant training time.




